目次
はじめに
「Juliaでランダムフォレストを動かしてみたけれど、ROC曲線ってどう読めばいいの?」「AUCが0.85と表示されたけれど、これって良いのか悪いのか分からない」そんなふうに、画面に出てきた数値やグラフを前に手が止まってしまうことはありませんか。
Juliaを使った機械学習では、ランダムフォレストのパラメータ調整とROC曲線による評価がセットで語られることがよくあります。けれど、実際にノートブックやエディタでコードを実行し、グラフが表示されても、「このカーブの形は何を意味しているのか」「AUCが少し上下したのはモデルが良くなったということなのか」と、頭の中が追いつかないまま次のセルを実行してしまうこともあるでしょう。
ROC曲線が左上に近いほど良い、と聞いていても、その「左上」がどんな予測結果を表しているのか具体的に思い浮かばないままだと、画面のグラフと自分が作っているモデルとが結びつきません。AUCの数値が0.7から0.8に変わっても、それがどんな違いなのか実感できず、数字だけが独り歩きしてしまいます。
この記事では、Julia環境でランダムフォレストを動かしながらROC曲線を確認する場面を、実際の作業の流れに沿って一つずつ整理していきます。コードを実行したあと、どこを見て、どんな状態を頭に描けばよいのかを、順を追って丁寧に言葉にしていきます。
ROC曲線とは?
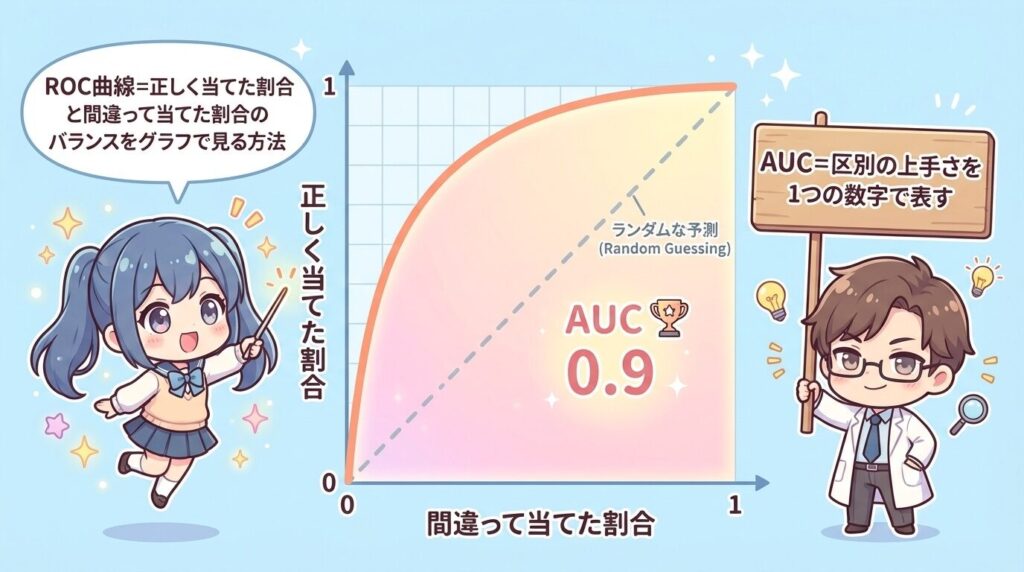
ROC曲線は、「2択の分類モデルが、当たり(陽性)とハズレ(陰性)をどれだけうまく見分けられているか」を、しきい値を動かしながら1枚のグラフで確かめるための図です。たとえば「不正利用かどうか」「病気かどうか」「解約しそうかどうか」を確率で出すモデルを使ったとき、警告を出す基準を厳しくしたり緩くしたりすると、見逃しと誤検知の出方が変わります。ROC曲線は、その変化をまとめて見て、表示された線を「自分のデータで、どのくらい拾えていて、どのくらい間違えているか」と結びつけて理解するために使います。
ROC曲線は「正しく当てた割合」と「間違って当てた割合」のバランスをグラフで見る方法
たとえば迷惑メール判定モデルをテストしたら、まず「迷惑メールをどれだけ拾えているか」と「通常メールをどれだけ巻き込んでいないか」をセットで確認してください。ROC曲線は、この2つをしきい値(迷惑メール扱いにする厳しさ)を変えながらグラフにしたものです。
具体的には、迷惑メール100通・通常メール900通のデータで、しきい値を変えて次のように数字を出します。
- しきい値を低くして“厳しさ”をゆるめる(=迷惑判定を出しやすくする)と、迷惑メールは多く拾えますが、通常メールも迷惑にしてしまう数が増えます
- しきい値を高くして“厳しさ”を上げる(=迷惑判定を出しにくくする)と、通常メールの誤判定は減りますが、迷惑メールを取り逃がしやすくなります
このとき、迷惑メールを正しく迷惑とできた割合(真陽性率)と、通常メールを誤って迷惑にした割合(偽陽性率)を、しきい値ごとに点として打って線でつないだものがROC曲線です。線が左上に寄るほど、「迷惑メールをしっかり拾いながら、通常メールを巻き込みにくい」状態になります。
AUCはその線の下の面積で、たとえばAUC=0.8なら、無作為に当てるよりも、迷惑メールと通常メールをはっきり区別できているイメージが持てます。
ROC曲線は「どれくらい上手に区別できているか」をAUCという1つの数字で表す
Juliaで学習したモデルを評価するときは、まずROC曲線を描いて形を目で確認し、次にAUCの数値を1つだけメモしてください。AUCは「このモデルが正例と負例をどれくらい上手に区別できているか」を、0〜1の1つの数字にまとめたものです。ROC曲線が対角線に近い形なら、画面を見た時点で「この判定は偶然とほぼ変わらない」と受け止めてOKです。つまり、正例と負例がきれいに分かれていません。逆に、左端から急に上へ伸びる形なら、通常メールを少しだけ迷惑扱いにしてしまう(偽陽性を少し許す)だけで、迷惑メールを多く拾えている状況が想像できます。
この“形の印象”を、AUCで短く言い換えるのがコツです。たとえばAUCが0.5付近なら「区別できていない」、0.8なら「かなり区別できている」、0.9以上なら「かなりきれいに分かれている」と捉えられます。ROC曲線の見た目とAUCの数字をセットで押さえると、モデルの当たり外れをその場で言葉にできます。
ROC曲線は「ある・ない」「陽性・陰性」のように2つに分ける問題で使う評価方法
ROC曲線は、答えが最終的に2つに決まる問題で使ってください。たとえば「迷惑メール/通常メール」「不正アクセス/正常」「病気あり/なし」のように、モデルが各データに対して確率(スコア)を返し、その数値に線を引いて「陽性にするか」「陰性にするか」を決められる場面です。しきい値を0.3、0.5、0.7…のように動かしながらROC曲線を描くと、「拾える陽性が増える代わりに、誤って陽性にしてしまう数がどれだけ増えるか」が画面上で追えます。
一方で、3クラス以上を同時に当てる多クラス分類では、ROC曲線を1枚でそのまま出せません。表示するなら「特定のクラス vs それ以外」を作って複数本のROCを並べる必要があり、見え方が一気に複雑になります。
また、確率ではなく固定ルールで結果が決まる分類(例:条件に当てはまったら即ブロック、のようにスコアを出さない仕組み)では、しきい値を動かして形を変える余地がないため、ROC曲線を描いても得られる情報が薄くなります。つまり「2値で、スコアに線を引いて決めるタイプ」ならROCを出し、「多クラス」や「固定ルール」ならROCを無理に出さず、別の見せ方に切り替える、という使い分けになります。
ROC曲線のAUCはどこで判断する?

AUCは、画面に出た数字だけで即決せず、まず「その0.7が出たときに、現場では困らないか」を自分のデータに当てはめて確かめます。同じ0.7でも、もともと見分けにくいデータを扱っているのか、誤判定がほとんど許されない場面なのかで、受け止め方が変わるからです。ROC曲線を開いたら、AUCの数値を眺めるだけで終わらせず、曲線の形も一緒に見て「検知を増やしたときに誤検知がどれだけ増えるか」を想像します。そうやって状況に置き換えると、表示されたAUCはただの数字ではなく、「このモデルをどの場面で使えるか」を考える材料になります。
AUCは0.6・0.7・0.8以上の数値ラインを目安にモデルを使うか判断する
AUCを見たら、まず0.6・0.7・0.8を区切りとしてメモし、モデルを使う前提をその場で決めてください。AUCはROC曲線の“形”を1つの数字にまとめたものなので、数字ごとに「画面にどんな線が出ているか」をセットで思い浮かべると、結果を誤解しにくくなります。
AUCが0.6台なら、ROC曲線は対角線から少し離れる程度で、正例と負例がまだ混ざっている状態です。「当たるときもあるが、外す場面も同じくらい出る」と捉え、これだけで運用に入れようとしないほうが安全です。
AUCが0.7台なら、ROC曲線がゆるやかに左上へ寄り、区別がある程度ついてきています。「使える場面はある」と見て、まずは限定的な用途(例:候補を絞って人が確認する)で使うイメージが合います。
AUCが0.8以上なら、ROC曲線が左端から立ち上がる形になり、少ない偽陽性で多くの正例を拾えている状態が想像できます。「機械の判定を前に出して使える」水準として扱いやすくなります。
数字を見たら、その数値に対応するROC曲線の形を頭に置きながら、「このモデルの結果をどこまで任せるか」を決めると、画面の評価が現実の運用に結びつきます。
AUCはROC曲線が対角線からどれだけ左上に離れているかで判断する
AUCを見るときは、まずROC曲線が対角線(当てずっぽうの線)からどれだけ左上に離れているかを確認してください。AUCはその“離れ具合”を面積でまとめた数値なので、数値だけを見ずに、曲線がどの区間で持ち上がっているのかも画面で一緒に追うのがコツです。
AUCが高く見えても、実データでは「一部だけ当たっている」ことがあります。たとえば、迷惑メール判定で“確信度が高い迷惑メール”はきれいに拾える一方、迷惑と通常の境目にいるメール(文面が似ている、短い、判断材料が少ないなど)が誤判定され続ける状況です。この場合、ROC曲線全体は良さそうに見えても、実際にしきい値を1つに固定して運用した瞬間、「思ったより通常メールが迷惑に入る」「逆に迷惑メールが抜ける」といった違和感が出ます。
つまり、AUCが高い=どの運用条件でも安心、とは限りません。ROC曲線が左上に寄っている区間と、寄り切らずに寝ている区間を見比べながら、「自分が固定したいしきい値付近で、誤検知が増えそうか」を想像しておくと、数値と現場の感覚のズレに気づきやすくなります。
AUCは実際に使う閾値での偽陽性の多さを見て最終的に判断する
AUCを見たら、その数字だけで「使える」と決めず、実際に運用で固定するしきい値での偽陽性がどれだけ出るかを必ず確かめてください。ROC曲線は、しきい値を動かしたときに真陽性率(拾える量)と偽陽性率(巻き込みの量)がどう入れ替わるかを並べた図なので、最後は「自分が置くしきい値の点」を見て決まります。
たとえば不正検知のように見逃しを減らしたいなら、しきい値を下げて疑わしいケースを多めに拾う設定にします。その代わり、偽陽性も増えます。逆に、誤判定の通知が多いと利用者が困る(サポート対応が増える、警告が無視される)場面なら、しきい値を上げて偽陽性が小さくなる点を選びます。その代わり、真陽性率は下がります。
同じROC曲線でも、運用で固定するしきい値が違えば、現場の体感はまったく変わります。AUCは全体の良さをまとめた数字として眺め、最後は「このしきい値で回したら、誤判定が何件出るか」を目で追って、数値と実際の作業感覚を一致させてから使うか決めてください。
ROC曲線・Precision-Recall・Accuracyはどの場面で使い分ける?

ROC曲線・Precision-Recall・Accuracyは、同じ分類モデルでも「どんな失敗が困るか」を思い浮かべて、開く指標を変えます。ROC曲線だけを眺めていると、ほかの指標が映している偏りに気づけないまま、良さそうに見える線だけで納得してしまうことがあります。そこで、ROCを見たらそれで終わらせず、Precision-Recallも開いて「当たったと言ったものの中に外れがどれだけ混ざるか」「本当に拾いたいものをどれだけ取りこぼすか」を確かめます。さらにAccuracyも確認して、全体の正解率が高く見えても、少数クラスをほとんど拾えていない状態が隠れていないかを見ます。こうして指標を並べて見ると、数式の違いではなく、同じ結果を別の角度から眺めたときに見えてくる状況の違いとして理解できます。
陽性データが少ないかどうかを基準に選ぶ
不正検知や故障予測のように、陽性(正例)が少ないデータを扱っているなら、ROC曲線だけで安心しないでください。まず自分のデータで「陽性がどれくらいの割合か」を確認し、少ないと分かった時点でPrecisionも必ず一緒に見ます。
陽性が少ないデータでは、全体の大半が陰性(負例)です。そのため、陰性を少し誤って陽性にしてしまっても、偽陽性率が小さく見えやすく、ROC曲線がきれいに見えることがあります。たとえば1万件中、陽性が100件(1%)しかない状況で、陰性9,900件のうち100件を誤って陽性にしても、偽陽性率は約1%に見えます。グラフ上は「左上に寄っていて良さそう」に感じても不思議ではありません。
ところがPrecisionを見ると、予測した陽性の中身がスカスカな場合があります。上の例だと、陽性と予測した200件(真陽性100+偽陽性100)のうち、当たりは半分でPrecisionは0.5です。さらに偽陽性が増えていれば、「陽性と出てもほとんど外れ」という状態になり、画面を切り替えた瞬間に違和感が出ます。つまり、陽性が少ないデータでは「ROCが良さそうに見える」だけで止めず、Precisionを見て「予測した陽性がどれくらい当たっているか」までセットで確かめると、評価と運用のズレに気づけます。
見逃しと誤検知のどちらを重く見るかで選ぶ
医療データや異常検知のように「陽性を見逃したくない」場面では、ROC曲線だけで終わらせず、PrecisionとRecallもセットで確認してください。まず、あなたの現場で困るのが「見逃し(陽性を陰性にしてしまう)」なのか、「誤検知(陰性を陽性にしてしまう)」なのかを決め、その優先度に合わせて見る画面を選びます。
見逃しを減らしたいなら、Recallがどこまで出ているかを最優先で見ます。ROC曲線が良さそうに見えるモデルでも、Recallが低くて重要な陽性を拾えていないことがあります。画面でRecallが伸びていないのに「ROCはきれいだからOK」とはしないほうが安全です。
一方で、誤検知が増えると運用が回らない(通知が多すぎる、確認作業が破綻する)なら、Precisionがどこまで保てているかを重く見ます。このときPrecision-Recallのグラフを開き、しきい値を動かしたときに曲線が急に落ち込む形になっていないかを確認すると、「少し設定を変えただけで当たりが一気に減る」場面が想像できます。同じモデルでも、ROC・AUCだけを見たときと、Precision-Recallを見たときで、画面の印象が大きく変わることがあります。だからこそ、見逃しと誤検知のどちらを重く扱うかを先に決め、その目的に合う指標の画面を開いて評価します。
実際に使うしきい値での誤判定の多さで選ぶ
Accuracyを最初に見たとしても、その数字だけでモデルを採用しないでください。実際に運用で固定するしきい値を決めたうえで、そのしきい値で誤判定がどれだけ出るかを確認してから選びます。Accuracyは分かりやすい反面、クラスの偏りが大きいと高く出やすいです。たとえば、データの99%が通常(陰性)で1%だけが異常(陽性)という状況では、すべてを「通常」と出すだけでもAccuracyは99%になります。画面に高い数値が出ても、「異常を拾えている」とは限りません。
そこで、ROC曲線やPrecision-Recallを開き、同じしきい値での動きを見比べます。ROC曲線やPrecision-Recallを確認すると、実際には陽性をほとんど拾えていない状態がそのまま出ることがあります。Accuracyが高く表示された瞬間こそ、別の指標の画面に切り替えて、誤判定の出方が現実の運用に耐えるかを確かめてください。
JuliaでROC評価からランダムフォレスト最適化までを一本化した実行フロー
JuliaでROC評価からランダムフォレスト最適化までを一本の流れにすると、「評価を見てから設定を変え、もう一度結果を確かめる」作業を、同じコードの中で迷わず回せます。機械学習を進めていると、ROC曲線を表示した直後にハイパーパラメータを調整し、すぐ次の実行で評価を見直す場面が何度も出てきます。コードを評価用・学習用に分けてしまうと、どの変更がどの結果につながったのかが追いにくくなり、操作と結果が頭の中で離れがちです。評価と最適化を同じ実行フローにまとめておけば、パラメータを触った直後にROCの形がどう変わったかをその場で確認でき、グラフの変化をそのままモデルの動きとして捉えられます。
フロー① 評価指標を決めてからデータを分割する
最初にやることは、データを分ける前に「何の指標でモデルを評価するか」を決めておくことです。Accuracyで見るのか、AUCで見るのか、PrecisionやRecallを重視するのかを先に書き出してから、データを学習用と検証用に分割します。
データを読み込み、特徴量とラベルに分け、たとえば8:2や7:3の割合で学習用と検証用に分ける場面では、まだROC曲線は表示されません。この時点では、どの数字で良し悪しを決めるのかを自分で固定しておきます。その後、ランダムフォレストなどで初期状態のモデルを学習させると、検証データに対する予測確率が画面に並びます。ここではまだパラメータ調整をしていないため、モデルの癖がそのまま数値に出ます。
評価指標を先に決めておけば、この予測確率からROC曲線やPrecision-Recallを描いたときに、「どの数値を見るか」で迷いません。数値の一覧がグラフに変わる段階で、自分が最初に決めた指標をそのまま当てはめて確認できます。
フロー② モデルを学習させてROC曲線を確認する
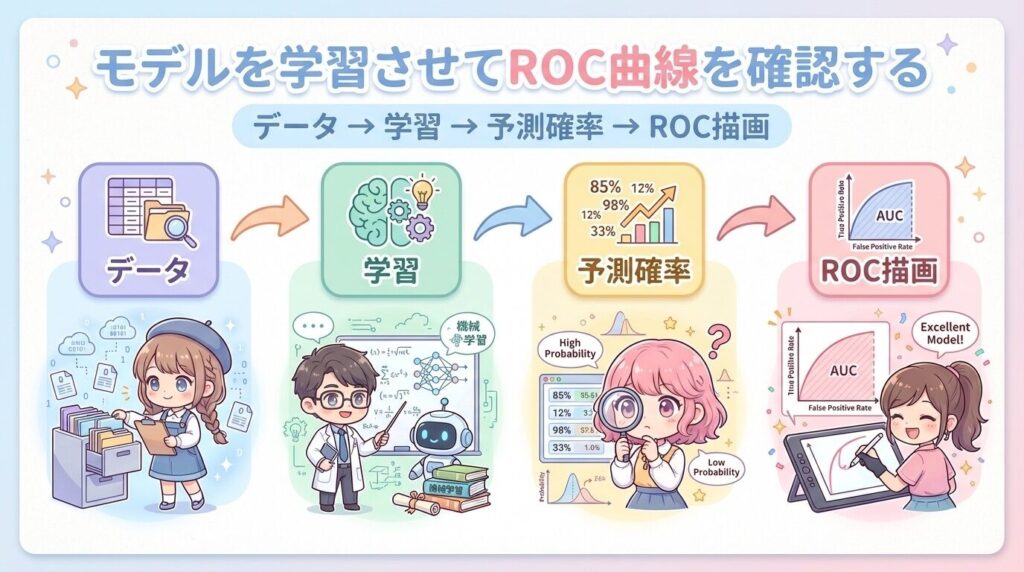
モデルを学習させたら、検証データに対して出た予測確率を使い、その場でROC曲線を描いてください。これが最初に確認するグラフになります。画面に出た曲線が対角線に近いのか、左上に寄っているのかをまず目で見て、今のモデルが「区別できていそうか」を掴みます。
次に、パラメータを1つだけ変えて再学習させ、もう一度ROC曲線を描き直します。たとえばn_treesを100→300に増やす、max_depthを5→10に変える、といった具合です。変更前の曲線と変更後の曲線を並べて見比べると、「いま触った設定が、偽陽性と真陽性の出方をどう変えたか」がそのまま形の違いとして出てきます。
この作業を繰り返すと、どの調整が曲線を左上に寄せるのか、逆に曲線を寝かせるのかが、画面の変化として少しずつ見えてきます。
フロー③ AUCと曲線の変化を見てパラメータを調整する
パラメータ調整は、ROC曲線とAUCを表示した直後に行い、そのまま再学習→再表示まで一気に回してください。評価を別のタイミングに回すと、「どの操作で曲線が変わったのか」が頭から抜けやすくなります。
具体的には、ROC曲線とAUCを出したら、その画面を見たままn_treesやmax_depthなどを1つだけ変更し、すぐに再学習させてROCとAUCをもう一度出します。変更前と変更後のAUCを並べ、曲線が左上に寄ったのか、逆に対角線へ戻ったのかを同じ流れの中で確認します。
この「評価→1項目だけ変更→再評価」を繰り返すと、曲線の変化がそのままモデルの振る舞いとして記憶に残ります。画面を行き来しながら、操作と結果を同じ流れの中で積み重ねられるので、調整の方向を見失いにくくなります。
JuliaのROC評価が正しく動かない3つの確認ポイント
JuliaでROC評価がうまく出ないときは、モデルの当たり外れを疑う前に、まず実行環境を3点だけ確認して止めます。ROC曲線やランダムフォレストは、コードそのものが同じでも、パッケージの読み込み順やバージョン差で表示結果が変わることがあります。ROC曲線が出ない状態で画面を眺め続けると、「モデルが悪いのか」「データが悪いのか」が分からないまま時間だけが過ぎます。最初に環境側を点検しておけば、原因が実行環境にあるのに設定や学習をいじり続ける、という回り道を避けられます。実行手順のズレでグラフが出なくなっている場合は、ここを整えるだけで表示が戻り、どこから直せばいいかも見えるようになります。
ポイント① MLJとDecisionTree系パッケージが正しく読み込まれているか確認する
MLJで決定木やランダムフォレストを呼び出す前に、MLJ本体だけでなくDecisionTree系のパッケージも読み込まれているかを最初に確認してください。MLJは表側の窓口で、実際の学習と予測はDecisionTree側が動いています。モデル定義のコードを書いても、DecisionTree系が読み込まれていないままだと、予測確率が返ってこないことがあります。エラーが出るとは限らず、画面には何も起きていないように見えるのに、予測結果だけが空になる場面もあります。
この状態に気づいたら、MLJとDecisionTree系を読み込んだうえで、同じコードをもう一度実行してください。パッケージが正しく読み込まれた瞬間に予測結果が表示され、「コードは同じなのに動き方が変わった」ことがはっきり分かります。
ポイント② 予測確率を出力してからROCを描画しているか確認する
ROC曲線を描く前に、モデルから「予測確率」が出ているかを必ず確認してください。クラスラベル(例:「陽性」「陰性」)だけをそのまま渡しても、ROCは正しく描けません。まず検証データに対して予測確率を出力し、その数値を使ってROCを作ります。
たとえば、0か1のラベルだけを取得している場合は、0.87や0.23のような確率が並んでいるかを画面で確かめてください。確率が表示されていなければ、ROC用の入力が足りていません。また、可視化ライブラリが読み込まれていないと、コードは最後まで実行されてもグラフが表示されないことがあります。ノートブック環境では、セルの実行順が前後しただけで、確率を出力する処理が飛んでいることもあります。
グラフが出ないときは、まず「モデルが悪い」と考えるのではなく、「確率を渡しているか」「必要なライブラリを読み込んでいるか」を画面で順番に確認してください。入力データの形式が整った瞬間に、ROC曲線は正しく表示されます。
ポイント③ 学習→予測→評価の順序が崩れていないか確認する
コードを実行するときは、「学習 → 予測 → 評価」の順番で必ず上から通して実行してください。途中のセルだけを動かすと、必要な変数が存在しないまま処理が走り、ROC曲線が表示されなかったり、エラーで止まったりします。たとえば、データを読み込む前にモデル学習を実行すると、特徴量やラベルの変数がまだ作られていないため、処理が途中で止まります。また、ROC曲線のセルだけを再実行した場合、直前に予測確率を出していなければ、グラフは空白になります。
ノートブック環境では、同じセルを何度も実行するうちに変数の中身が上書きされていることもあります。前回と同じつもりで実行しても、表示される結果が微妙に違うのは、実行順が崩れている可能性があります。画面の挙動がおかしいと感じたら、上から順番に「データ読み込み → モデル学習 → 予測確率の出力 → ROCなどの評価」を通しで実行し直してください。順序が整っていれば、1行ずつ進むごとに結果が自然につながって表示されます。
ランダムフォレストのパラメータを変えるとROC曲線はどう変わる?

ランダムフォレストのパラメータを触ったあとにROC曲線を描き直すと、同じデータでも曲線の立ち上がり方やなだらかさが変わって見えます。たとえば数値を1つだけ変えたのに、昨日まで左上に寄っていた線がゆるくなったり、逆に最初だけ急に持ち上がったように見えたりすることがあります。画面に出た曲線の違いは、内部で作られる決定木の本数や深さが変わった結果として現れます。ROCを表示してパラメータを調整し、もう一度ROCを出して比べる、という操作を繰り返すと、「この設定変更がグラフの形にこう出る」というつながりが目で追えるようになり、操作が結果にどう反映されているのかが視覚的に分かります。
n_treesを増やすと予測が安定しROC曲線の形が滑らかになりAUCの変動が小さくなる
n_trees(決定木の本数)を増やしたら、同じ検証データでROC曲線とAUCをもう一度出して、形と数値の変化を確認してください。本数を増やすと、各サンプルの予測確率が平均化され、ばらつきが小さくなります。たとえばn_trees=50のときにROC曲線がぎざぎざしているなら、100や300に増やして再学習させ、その都度ROCとAUCを表示します。本数が少ない状態では、1本1本の木の影響が大きく、サンプルごとの予測が揺れやすいため、曲線も不安定になりがちです。
本数を増やしていくと、曲線がなめらかになり、AUCの値も実行ごとに大きく上下しにくくなります。変更前と変更後のグラフを並べて見ると、「木の本数を増やしたこと」がそのまま形の安定として目に見えます。
max_depthを深くすると訓練データではROCが良くなるが検証データでは悪化することがある
max_depthを変更したら、必ず「訓練データ」と「検証データ」の両方でROC曲線とAUCを表示して見比べてください。片方だけを見て良し悪しを決めないことが大切です。たとえばmax_depthを5から20に増やすと、各決定木が細かい分岐まで覚えるため、訓練データではROC曲線が左上に寄り、AUCも高くなりやすくなります。画面上では「かなり良くなった」と感じる形が出ます。
しかし同じ設定で検証データのROCを描くと、曲線が対角線に近づいたり、AUCが下がったりすることがあります。これは訓練データに合わせすぎた結果です。この状態を確認したら、max_depthを少し浅く戻し(例:20→10や8)、再度両方のROCを表示します。訓練データの曲線は少し下がりますが、検証データの曲線が安定していれば、その設定のほうが実運用に近い振る舞いになります。
max_depthを触るときは、必ず「訓練と検証の両方のグラフを同時に確認する」という形で進めると、過学習が画面上の変化としてはっきり見えてきます。
特徴量を増やしすぎるとAUCが不安定になり曲線の形が毎回変わりやすくなる
特徴量の数(各分岐で使う特徴量の上限)を変更したら、同じデータ・同じ分割で複数回学習させ、毎回のROC曲線とAUCを並べて確認してください。1回だけの結果で決めず、形と数値の揺れを見ます。たとえば、全特徴量を毎回使う設定にすると、各決定木が似た分岐を選びやすくなり、木同士の違いが小さくなることがあります。その結果、AUCが実行ごとに0.82→0.78→0.84のように上下し、ROC曲線の形も毎回少しずつ変わることがあります。
逆に、各分岐で使う特徴量を絞る(例:全体の平方根程度にする)と、木ごとに異なる特徴量が選ばれやすくなり、予測確率の分布が広がります。このときAUCが0.80前後で安定し、ROC曲線の形も大きく崩れにくくなる場合があります。設定を変えたら、AUCの小数第2位や第3位の揺れだけでなく、ROC曲線の形が毎回大きく動いていないかを画面で確認してください。毎回形が大きく変わるなら、その設定は安定していません。曲線とAUCが似た形で落ち着く設定を選ぶと、再学習しても結果がぶれにくくなります。
ROC改善を目的にしたパラメータ探索手順とGridSearchをそのまま使わない理由
ROCを良くしたいなら、パラメータ探索は「精度の数字だけを上げる作業」にせず、ROC曲線の形がどう変わったかを毎回見てから次の設定を触ります。ROC曲線を出したまま調整すると、AUCなどの数値と、曲線が左上に寄ったのか・なだらかになったのかが同時に目に入るため、「どの変更が効いたのか」を体感しやすくなります。
逆に、精度だけを見て探索を回すと、ROC曲線がどちらに動いたのかを後から思い出せなくなる場面があります。GridSearchをそのまま走らせると、組み合わせが一気に計算されて結果がまとめて並ぶので、どの設定が曲線を押し上げたのかを画面上で追いかけにくくなります。ROCの形を意識した探索では、設定を少し変えてROCを描き直し、画面の変化を1つずつ確かめながら調整していく流れが自然に合います。
ROC(AUC)を基準にしてからパラメータ探索を始める
まず、初期設定のモデルでROC曲線とAUCを表示し、その形と数値を「出発点」として保存してください。AUCが0.72で、曲線が対角線より少し左上に寄っている、といった状態を最初の基準にします。
そのうえで、パラメータを1つだけ変更し、再学習→ROCとAUCを再表示します。たとえばn_treesを100→300に増やした結果、AUCが0.72→0.76に上がり、曲線がやや左上に寄ったなら、その変化をそのままメモします。次にmax_depthを変えたときも、同じように基準との差だけを見ます。ROCを基準にしておくと、「今触った設定でどれだけ曲線が動いたか」がはっきり分かります。最初のグラフを見ないまま複数のパラメータを同時に変えると、どの操作が効いたのかが分からなくなります。
毎回、基準のROC・AUCと並べて確認しながら1項目ずつ変更すると、画面の変化がそのまま操作の結果として積み重なります。
GridSearchはAccuracy最適化に偏りやすくROC改善につながらない理由
GridSearchを使うときは、評価指標をAccuracyのままにせず、AUCやROC関連の指標を明示的に指定してください。Accuracyだけで最適化すると、ROC曲線がほとんど改善していない設定を選んでしまうことがあります。たとえばAccuracyが0.95と表示されても、ROC曲線を開くと対角線に近い形のまま、AUCが0.60台にとどまっている場合があります。クラスの偏りが大きいデータでは、陰性を多く当てるだけでAccuracyは高くなりますが、陽性と陰性の区別がうまくなったとは限りません。
GridSearchの結果を確認するときは、まず最良とされたパラメータでROC曲線とAUCを表示し、曲線が本当に左上へ寄っているかを確かめてください。Accuracyが上がっていても、ROCの形が変わっていなければ、その設定は「当たりやすい側に寄っただけ」です。つまり、GridSearchを回す前に評価指標をAUCに変更するか、少なくとも最終的にROCを必ず確認するようにすると、数値だけが良く見える状態に引っ張られにくくなります。
AUCが伸びなくなった時点で探索するパラメータの範囲を見直す
AUCが何度調整してもほとんど伸びなくなったら、同じ範囲の中で細かく触り続けるのをやめて、探索するパラメータの範囲そのものを広げるか絞り直してください。たとえばAUCが0.81前後で止まり、n_treesを200→300→400と増やしても0.81〜0.82の間を行き来するだけなら、本数をさらに細かく増やすよりも、max_depthや特徴量数の範囲を変えたほうが変化が出やすくなります。
同じ設定の近い値を何度も試していると、ROC曲線の形もほとんど変わらず、「どこが良くなったのか」が見えなくなります。その状態になったら、今試している値の刻み幅を変える、探索の上限・下限を広げる、といった操作に切り替えます。ROC曲線が横ばいで、AUCも小数第2位までほぼ動かないなら、「今の範囲では伸びない」と受け止めて、試すパラメータの幅を見直してください。同じ場所を繰り返すより、探索の枠を変えるほうが次の変化につながります。
陽性が少ないデータでROC曲線のAUCを評価するときの注意点
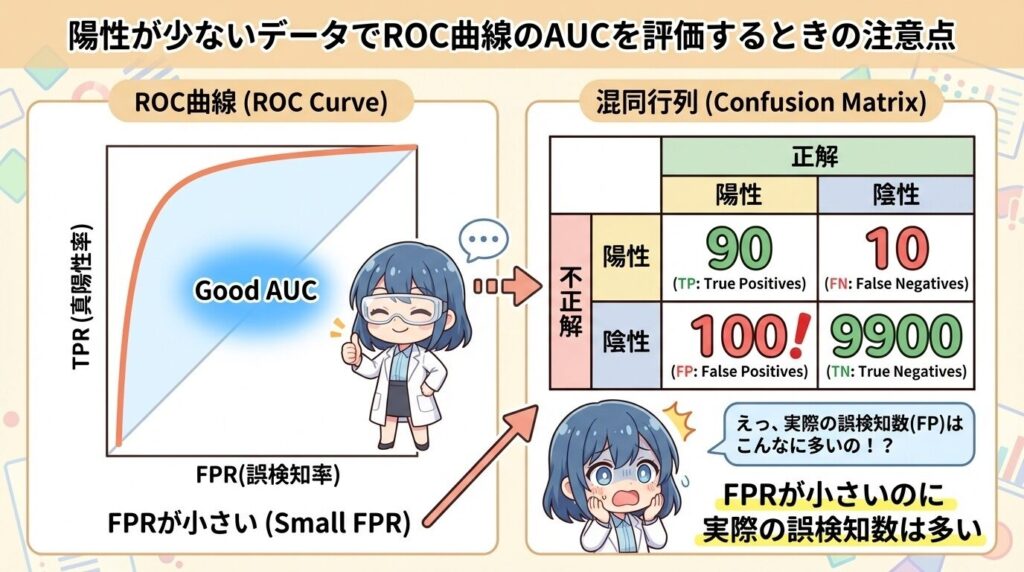
陽性が少ないデータでAUCを見るときは、きれいに見えるROC曲線だけで安心せず、実際にどのデータを当ててどれを外しているのかまで確認します。正例と負例の数に大きな差がある場合、画面に表示された曲線が左上に寄っていても、個別の予測結果を開くと「本当に拾いたい陽性をほとんど当てられていない」という状況が隠れていることがあります。陽性が少ない環境では、数件の誤判定でも全体の印象が大きく変わります。同じAUCの値でも、陽性が全体の数%しかないデータなのか、半分近くを占めているデータなのかで、実際の使いどころは大きく変わります。AUCの数字を見たら、そのまま結論にせず、予測ラベルや混同行列も開いて、どのクラスをどれだけ拾えているのかを具体的に確かめます。
偽陽性率が低く表示されても実際の誤検知件数が少ないとは限らない点に注意
ROC曲線で偽陽性率(FPR)が低く表示されても、そのまま安心せず、必ず「実際に何件の誤検知が出ているか」を数で確認してください。割合だけでなく、件数を横に並べて見ます。
たとえば1,000件中990件が負例のデータで、10件を誤って陽性にした場合、偽陽性率は約1%です。グラフ上では左側に寄り、「誤判定が少ない」ように見えます。しかし実際には10件の誤検知が発生しています。運用で1日1,000件を処理するなら、毎日10件の誤通知が出る計算になります。
さらに負例が10万件ある状況で偽陽性率が0.5%なら、割合は小さくても誤検知は500件です。ROC曲線の見た目が安定していても、現場では大量の誤通知が発生します。ROCを見るときは、表示されている偽陽性率に対応する「誤検知の件数」を具体的に計算してください。割合と件数を同時に確認すると、グラフの印象と実際の運用負荷の差に気づきやすくなります。
AUCが高く表示されても実際に陽性を多く拾えているとは限らない点に注意
AUCが高く表示されても、その数字だけで「陽性をたくさん拾えている」と決めないでください。特に陽性が少ないデータでは、確信度の高い一部だけを当てられるだけでAUCが高く見えることがあります。まずROC曲線を見たあと、実際に運用で固定するしきい値を1つ決め、そのしきい値で拾えた陽性の数を確認します。
たとえば陽性が100件しかないデータで、AUCが0.90と出ても、しきい値を0.5に固定した瞬間に拾える陽性が20件しかない(残り80件を取り逃がす)ことがあります。ROC曲線の全体像は左上に寄っていて良さそうに見えるのに、予測リストを開くと「陽性がほとんど出ていない」と感じる場面です。
このズレを避けるには、AUCを見た直後に、同じモデルの予測確率リストを開き、固定したしきい値で陽性判定になった件数と、その中に本当の陽性がどれだけ含まれているかを確認してください。ROCの見た目が良くても、固定しきい値での結果が弱ければ、実運用では「拾えていない」状態になります。AUCは全体の区別の良さを示す数字として受け取り、最後は「固定したしきい値で、陽性を何件拾えているか」を数字で確かめると、画面を切り替えたときに印象が崩れにくくなります。
ROC曲線だけで判断せず陽性と陰性の件数割合を必ず確認する
ROC曲線を見る前に、学習データと検証データそれぞれで「陽性が何件で、陰性が何件か」を必ず数えてください。ROCの形だけを先に眺めると、曲線が変わった理由が分からなくなります。
たとえば学習データでは「陽性200件・陰性800件」だったのに、検証データでは「陽性20件・陰性980件」のように割合が変わっていると、同じモデルでもROC曲線の見え方が変わります。学習時に左上へ寄っていた曲線が、検証では対角線に近づいて見える場面も起きます。
このとき「モデルが急に悪くなった」と決めつけず、まず件数の違いを画面で確認してください。陽性と陰性の割合が違えば、ROC曲線が同じ感覚で見えないのは自然です。ROC曲線は最後に見るグラフとして置き、毎回「学習と検証の陽性・陰性の件数」を先に確認すると、曲線の形の変化をデータの変化として受け止めやすくなります。
ROC曲線を見てどの閾値でモデルを採用するかを決める基準
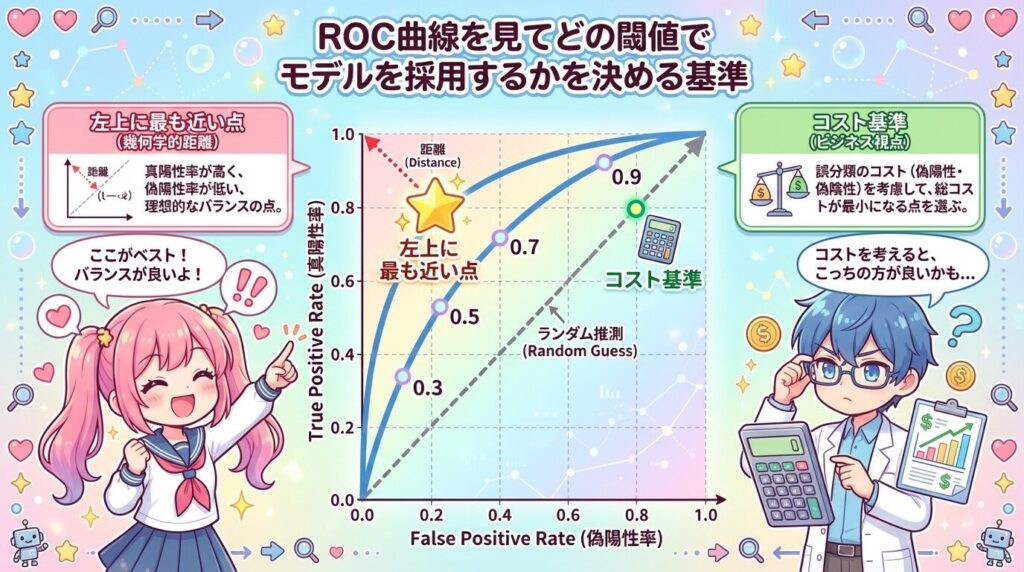
ROC曲線で閾値を決めるときは、曲線を表示したら終わりにせず、「どこで陽性と判定するか」を自分の運用に当てはめて一点を選びます。しきい値を動かすと真陽性率と偽陽性率の組み合わせが変わり、同じROC曲線でも「陽性を多く拾う代わりに誤検知が増える」「誤検知を減らす代わりに見逃しが増える」といった状況が入れ替わります。グラフを見ながら各点の数値を確認していくと、どのあたりで判定が切り替わり、予測がどんな状態になるのかが具体的に想像できるようになります。曲線上の一点を選ぶ瞬間に、モデルが現場でどう振る舞うかが、数字ではなく場面として見えてきます。
偽陽性と偽陰性のどちらを許容するかで閾値を決める
しきい値を決める前に、まず「誤検知(偽陽性)」と「見逃し(偽陰性)」のどちらを増やしたくないかを決めてください。ROC曲線は、しきい値を変えたときに真陽性率と偽陽性率がどう動くかを見せるグラフなので、最初に方針を決めないと、どの点を選べばいいか迷います。
見逃しが重大になる仕事(医療診断や不正検知など)では、しきい値を下げて陽性を拾いやすくし、真陽性率が高い位置を選びます。その代わり、通常データまで陽性にしてしまうケースが増えます。たとえば「疑わしいものは一旦全部アラートに出して、人が確認する」運用に寄せるイメージです。
一方で、誤検知が増えると現場が回らない仕事(大量通知が飛ぶ、顧客対応が発生するなど)では、しきい値を上げて偽陽性率が低い位置を選びます。その代わり、見逃しが増える可能性があります。たとえば「本当に確信があるものだけ通知して、それ以外は通知しない」運用です。つまり、しきい値はROC曲線の形だけで決めるのではなく、「誤検知と見逃しのどちらを許容する運用にするか」を先に決め、その方針に合う位置をROC上で選んで固定します。
運用時の誤検知コストを基準に採用ラインを決める
モデルを採用する前に、まず「誤検知1件あたりにどれだけの手間や費用がかかるか」を具体的に書き出してください。たとえば、誤検知が1件出るたびに5分の目視確認が必要で、1日1万件を処理する業務なら、偽陽性率が0.5%でも50件の誤検知が発生します。確認作業だけで250分かかる計算です。
このように実際の件数と作業時間に置き換えたうえで、ROC曲線を開きます。まず「これ以上は対応できない」と決めた偽陽性率の上限を設定し(例:0.2%以内)、その範囲内で真陽性率が最も高い点を選びます。逆に、多少の誤検知が許容できる業務(例:自動で軽い通知を出すだけ)であれば、偽陽性率が少し上がっても、真陽性率が高くなる位置を選びます。
採用ラインは、AUCの高さや見た目の良さではなく、「その誤検知件数を毎日処理できるか」で決めます。ROC上の数値を、実際の件数と作業時間に置き換えてから最終的なしきい値を固定してください。
ROC曲線上で左上に最も近い点を候補にする
特別な制約がない場合は、ROC曲線上で左上に最も近い点をしきい値の候補にしてください。左上に近いほど「真陽性率が高く、偽陽性率が低い」状態です。
具体的には、各しきい値での真陽性率(TPR)と偽陽性率(FPR)を一覧にし、「TPR − FPR」が最大になる点(Youden指数が最大の点)を探します。たとえば、
- しきい値A:TPR 0.80、FPR 0.30 → 差は0.50
- しきい値B:TPR 0.75、FPR 0.10 → 差は0.65
この場合は、差が大きいBを候補にします。数値で確認したうえで、実際の誤検知件数も合わせて確認します。
複数モデルを比べるときも、AUCの大小だけで決めず、曲線がどれだけ左上に寄っているかを実際に重ねて表示して見ます。AUCがほぼ同じでも、あるモデルは序盤で急に立ち上がり、別のモデルは後半で伸びるなど、形が違うことがあります。
最終的には、
- 誤検知と見逃しのどちらを優先するか
- 実際の運用で処理できる誤検知件数か
- ROC上で左上に最も近い位置か
この3つを画面で確認し、その条件を満たす点を採用します。
まとめ
JuliaでROC曲線とランダムフォレストを扱うときは、最初にROC(AUC)を評価基準に決め、そのうえでデータを分割し、学習→予測確率の出力→ROC描画という順番を崩さず実行します。確率ではなくクラスラベルを渡していないか、パッケージが正しく読み込まれているかも毎回確認します。
パラメータは一度にまとめて変更せず、n_treesやmax_depth、特徴量数を1つずつ調整し、その直後にROC曲線とAUCを表示します。変更前後の曲線を見比べることで、どの操作が曲線を左上へ寄せたのか、どの設定で検証データが崩れたのかを画面上で把握できます。
AUCが高くても陽性を十分に拾えていない場合や、偽陽性率が低く見えても誤検知件数が多い場合があります。ROCの形だけで決めず、陽性・陰性の件数割合と実際の誤検知数も必ず確認します。
最終的な閾値や採用ラインは、偽陽性と偽陰性のどちらをより許容するか、そして運用時の誤検知コストに耐えられるかで決めます。数値やグラフの印象だけでなく、実際の業務負荷を想定したうえで、左上に近い点を候補として選びます。
ROC曲線は「きれいな形かどうか」を眺めるためのものではなく、操作と結果を結びつけるための確認画面です。評価と調整を同じ流れの中で繰り返すことで、モデルの振る舞いを具体的に理解できるようになります。